
출처 : 프로그래머스 코딩테스트 연습, https://programmers.co.kr/learn/courses/30/lessons/42626
코딩테스트 연습 - 더 맵게
매운 것을 좋아하는 Leo는 모든 음식의 스코빌 지수를 K 이상으로 만들고 싶습니다. 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 Leo는 스코빌 지수가 가장 낮은 두 개의 음식을 아래와 같
programmers.co.kr
Heap을 사용하면 금방 풀리는데 분석하는데 오래 걸렸다.
우선순위 Queue를 사용해서 풀기도 하던데 그건 안해봄
첫 번째 풀이 : Heap 사용
def solution(scoville, K):
import heapq
min_heap = []
for i in scoville:
heapq.heappush(min_heap, i)
count = 0
while True:
min_scoville = heapq.heappop(min_heap)
if min_scoville < K:
count += 1
try:
second_scoville = heapq.heappop(min_heap)
new_scoville = min_scoville + second_scoville * 2
heapq.heappush(min_heap, new_scoville)
except:
return -1
else:
break
return count
처음 생각한 로직은 간단하다.
1. scoville을 크기 순으로 정렬(min-Heap에 넣으면 자동 정렬)
2. 가장 작은 값이 K보다 작다면(미만) 가장 작은 값과 두 번째로 작은 값으로 새로운 scoville을 만들어 삽입
3. 값이 하나만 남았을 때, K보다 작다면 K 이상으로 만들 수 없으므로 return -1
(값이 하나만 남은 상태에서 second를 불러올 때 에러가 남을 이용하여 try~except문으로 해결)
로직만 봤을 때는 list로도 충분해보인다.
그렇다면 왜 힙을 써야할까?
동일한 로직을 list로 구현해보았다.
두 번째 풀이 : 리스트 사용, 효율성 테스트 실패
def solution(scoville, K):
scoville.sort(reverse=True)
count = 0
while True:
min_val = scoville.pop()
if min_val < K:
count += 1
try:
second_val = scoville.pop()
new_val = min_val + second_val * 2
scoville.append(new_val)
scoville.sort(reverse = True)
except:
return -1
else:
break
return count
위의 코드와 큰 차이는 없지만 scoville을 크기의 역순으로 정렬하여 끝에서 빼는 방식으로
첫 번째 풀이와 동일한 로직을 구현하였다.
그리고 이 풀이는 정확성 테스트는 모두 통과했지만, 효율성 테스트에서 실패하였다.
시간 복잡도
사실 Heap도 O(NlogN)이고 sort() 함수도 O(NlogN)으로 알고 있는데 왜 실패할까?
검색해봤더니 다음과 같은 글을 보았다.
If you use binary heap to pop all elements in order, the thing you do is basically heapsort. It is slower than
sort algorightm in sorted function apart from it's implementation is pure python.
The heapq is faster than sorted in case if you need to add elements on the fly i.e. additions and insertions
could come in unspecified order. Adding new element preserving inner order in any heap is faster than
resorting array after each insertion.
The sorted is faster if you will need to retrieve all elements in order later.
The only problem where they can compete - if you need some portion of smallest (or largest) elements
from collection. Although there are special algorigthms for that case, whether heapq or sorted will be
faster here depends on the size of the initial array and portion you'll need to extract.
출처 : https://stackoverflow.com/questions/24666602/python-heapq-vs-sorted-complexity-and-performance
Python heapq vs. sorted complexity and performance
I'm relatively new to python (using v3.x syntax) and would appreciate notes regarding complexity and performance of heapq vs. sorted. I've already implemented a heapq based solution for a greedy '...
stackoverflow.com
즉,
heap에서 모든 성분을 뽑아낼 때, Heap은 Heap Sort로 정렬하게 되는데
이는 원래 sort 함수(sorted 함수)보다 느리다.
그러나 성분을 배열에 넣고 이를 재배열해야하는 것은 오히려 sort함수보다 heap이 빠르다.
라는 내용이다.
이를 바탕으로 위를 보았을 때, 로직의 핵심은 만들어진 스코빌을 다시 배열에 넣고 이를 재정렬하는 것이 반복되므로
이 부분에서 heap을 사용하는 것이 sort함수를 사용하는 것보다 빨라
heap을 사용한 풀이는 효율성 테스트를 통과하지만, sort를 사용한 풀이는 통과하지 못한다는 것을 알 수 있다.
다른 사람의 풀이를 보면서 알게 된 점
Heapify
for i in scoville:
heapq.heappush(min_heap, i)
힙을 만들고 일일이 넣어주었는데
heapq.heapify(scoville)
그냥 heapify 함수 쓰면 된당 ㅎㅎ
2개의 Queue를 이용한 풀이
이 코드는 덧글 상에만 존재하고 실제 코드는 없어서 덧글 상의 정보를 바탕으로 적어봤다.
내가 적어서 좀 길지 아마 다른 분들이 적었다면 훨씬 짧을 거다. 그리고 길어도 그렇게 어렵진 않다.
사실 로직만 보면 된다.
def solution(scoville, K):
from collections import deque
INF = 9223372036854775807 #정수 최댓값
count = 0
scoville = deque(sorted(scoville)) #원래 scoville
mix = deque() #새로운 값
while True:
min_val = INF
if len(mix) == 0:
#mix가 비었다면 scoville의 왼쪽 값을 min값으로 설정
min_val = scoville[0]
if min_val < K:
min_val = scoville.popleft()
try:
second_val = scoville.popleft()
except: #하나 밖에 없는 원소가 K보다 작다면
return -1
new_val = min_val + second_val * 2
mix.append(new_val)
count += 1
else:
return count
else:
#mix가 비지 않았다면 두 queue 중 최솟값을 설정
if scoville[0] <= mix[0]:
min_val = scoville.popleft()
else:
min_val = mix.popleft()
if min_val < K:
#scoville이나 mix가 비었을 수도 있음
temp1 = INF
temp2 = INF
if len(scoville) > 0:
temp1 = scoville[0]
if len(mix) > 0:
temp2 = mix[0]
if temp1 == INF and temp2 == INF:
#둘 다 비었으면 하나 밖에 없는 원소 < K이므로 return -1
return -1
second_val = scoville.popleft() if temp1 <= temp2 else mix.popleft()
new_val = min_val + second_val * 2
mix.append(new_val)
count += 1
else:
return count
#scoville이 비었다면 mix의 모든 원소를 scoville로 옮김
if len(scoville) == 0:
while len(mix) > 0:
scoville.append(mix.popleft())
로직은 다음과 같다.
- scoville : 원본 값들이 들어있는 Queue
- mix : 섞어서 만들어진 값이 추가되는 Queue
1. scoville과 mix의 첫 번째 값 중 작은 값을 골라 min_val로 설정한다.
2. 가장 작은 값이 K보다 작은지 확인한다 -> K보다 크다면 END
3. K보다 작다면 scoville과 mix의 첫 번째 값 중 작은 값을 뽑아 second_val로 설정한다. -> 실패시 return -1
4. 두 값으로 만들어진 new_val을 mix에 넣는다.
6. mix와 scoville 중 한 쪽이 빈다면 역할을 바꿔가며 반복
나는 6번에서 mix와 scoville을 바꾸기 싫어서 조건문을 mix가 비었을 때와 아닐 때로 구분하여 작성하였고,
마지막에 scoville이 비었으면 mix의 모든 값을 scoville로 이동하는 코드를 작성하였다.
(scoville과 mix가 둘 다 내용물이 있거나 scoville만 내용물이 있는 경우로 강제하기 위해)
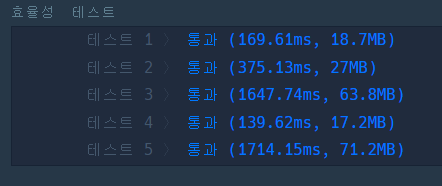
이 풀이의 시간 복잡도는 O(N)
실제로 효율성 테스트에서 걸리는 시간도 약 2배가량 짧다.
(대신 코드를 작성하는 노력에서 차이가 난다 ㅎ)
| Heap을 이용한 풀이 | 2개의 Queue를 이용한 풀이 |
 |
 |
고찰
이 문제를 풀면서 깨달은건데 나는 분해를 못한다.
로직을 한 번에 상상해서 한번에 코드를 주루룩 작성해서 구현하려고하니까 실수점을 찾지 못하는 것 같다.
분해하는 연습을 해야할 듯.
그리고 2개의 Queue를 이용한 풀이를 풀면서 했던 착각인데
scoville 원소의 범위가 0부터 1,000,000이라서 INF를 1,000,001로 설정했다가
단체로 런타임 에러 나와서 살짝 멘탈이 가출했다가 돌아왔다.
섞인 값은 1,000,001보다 클 수도 있는데 이를 생각하지 못해서
second_val의 삼항 연산자 부분에서 조건을 잘못 만족해 빈 리스트에 popleft를 한게 문제였다.
최대, 최소값을 설정할 때, 과연 그게 최대, 최소값이 맞는지 확인할 것.
'알고리즘 > Python' 카테고리의 다른 글
| [python] 프로그래머스 - H-Index (0) | 2022.02.14 |
|---|---|
| [python] 프로그래머스 - 가장 큰 수 (0) | 2022.02.14 |
| [python] 프로그래머스 - 주식 가격 (0) | 2022.02.13 |
| [python] 프로그래머스 - 기능 개발 (0) | 2022.02.10 |
| [python] 프로그래머스 - 다리를 지나는 트럭 (0) | 2022.02.09 |